















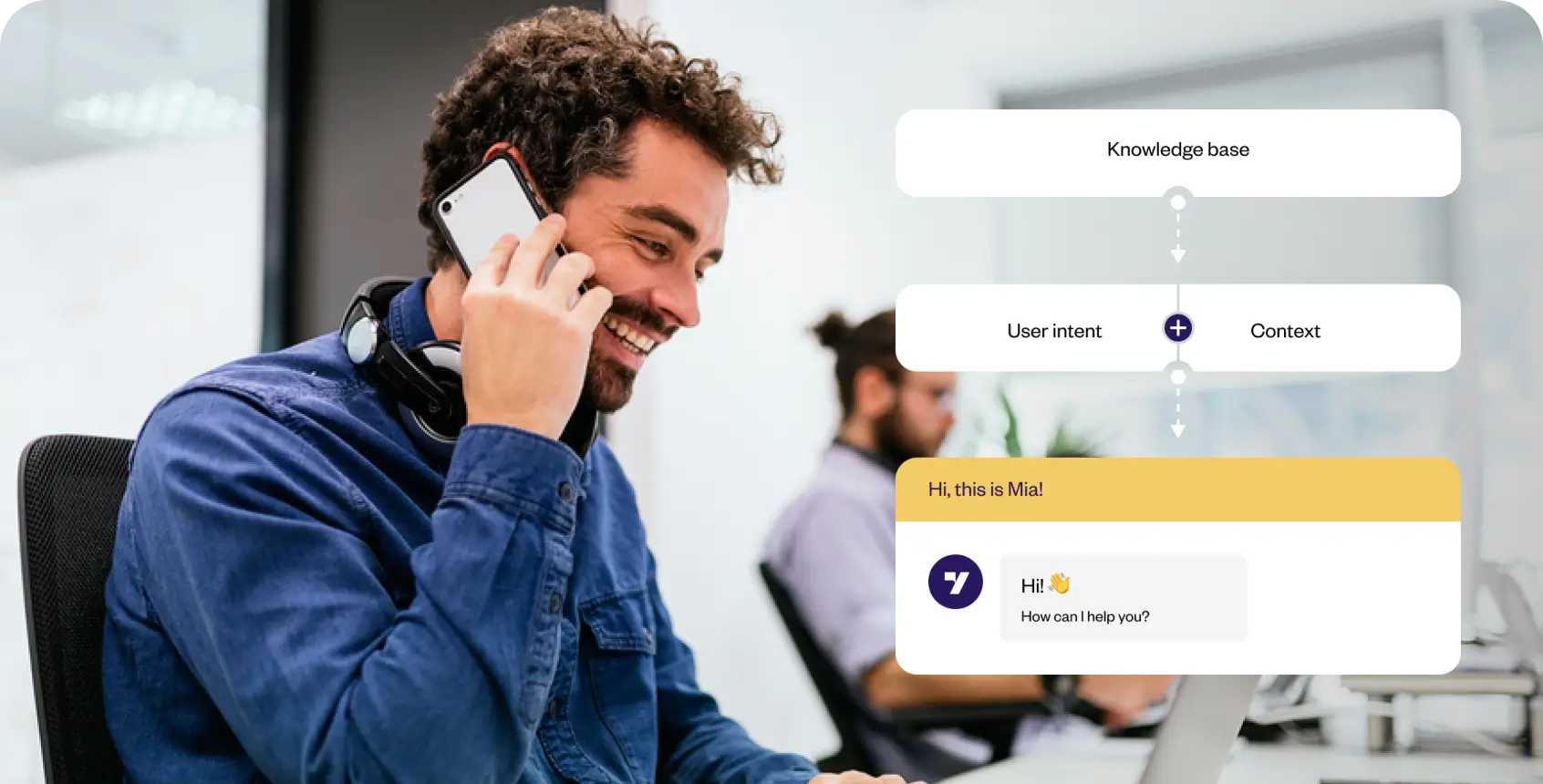
When designing and developing dynamic AI agent applications, commonly known as chatbots, it is important to have a good understanding of what is meant by “utterances”.
Most of these dynamic AI agent applications are designed by organizing utterances into intents, but there is a gray area between what intents and utterances are.
Understanding how “intents” and “utterances” fit into the creation of a great conversational AI experience depends heavily on the conversation design. Now, let’s understand utterances, intents, entity identification and how they’re different from each other.
Defining intent, entity and utterance suggestions
In simple terms, “intent” is the intention of the end-user that the Dynamic AI Agent (bot) receives. It’s all about what the end-user wants to get out of the interaction.
The intent is a critical factor because the Dynamic AI Agent’s ability to parse Intent from utterance Entity is what ultimately determines the success of the interaction. In order for a bot to be successful in its interaction, it must:
- Be trained effectively on NLP models having a good amount of training data from a variety of sources.
- Constantly improving and advancing based on how a user actually interacts with the bot with the help of Machine Learning (ML).
What is an Entity?
Knowing the difference between Intent and Entity is crucial as Intent implies what the end-user is looking for.
For example, a user queries, “Need Nike or Adidas running shoes in Berlin”.

Here the intent is to search/browse for running footwear while the entity is “Nike”, “Adidas” and “Berlin” as they specify the specific information the user is looking for.
The Dynamic AI Agent attempts to “identify the meaning” of the message in order to provide a tailored response that would make the conversational experience more fulfilling and engaging.
And what enables the Dynamic AI agents to respond this way is the NLP engine – which allows the bot to understand the language as used in natural, day-to-day conversations.
What are utterances?
Utterances are anything that an end-users will type or say and they are very closely connected to intents.
For example, if a user types “show me today’s national news,” that entire sentence is the utterance.
Utterances are essential inputs that are provided to the Dynamic AI Agent. It can either be via text or voice/audio inputs and the AI agent will then attempt to derive intents and entities from these utterances.
In order to make sure that your bot correctly identifies the intents and entities from the user-generated messages with a high degree of accuracy, the bot will need to train on a model with a variety of different example utterances for each and every intent.
After integrating these permutations and combinations into the bot’s intents and entities, end-users can then have a more human-like conversation with the bot.
The key here is to have as many utterances as possible. The more utterances a chatbot knows, the more chance it will understand a user and properly reply to them.
Why do you need utterance suggestions in bots?
Training of bots is very time-consuming, and the reason is that usually when customers are onboard, they don’t have a lot of data and the process of training involves understanding the ways in which a query can be asked – for example, different ways of checking “what’s the order status” and this is a very laborious process.
The outcome of not doing this training correctly is that the accuracy on NLP models will be extremely poor, leading to longer GTM deployments which will be a red flag.
Enter Yellow.ai: Your go-to partner in designing and delivering delightful experiences
With Yellow.ai’s Conversational Studio – where delightful User Experiences are created by leveraging cutting-edge NLP techniques, customers can now go live faster and train their bots faster and GTM faster with greater accuracy!
For example: This IT services bot needs to be trained on the use case of “forgot/reset password” as it doesn’t understand the intent.
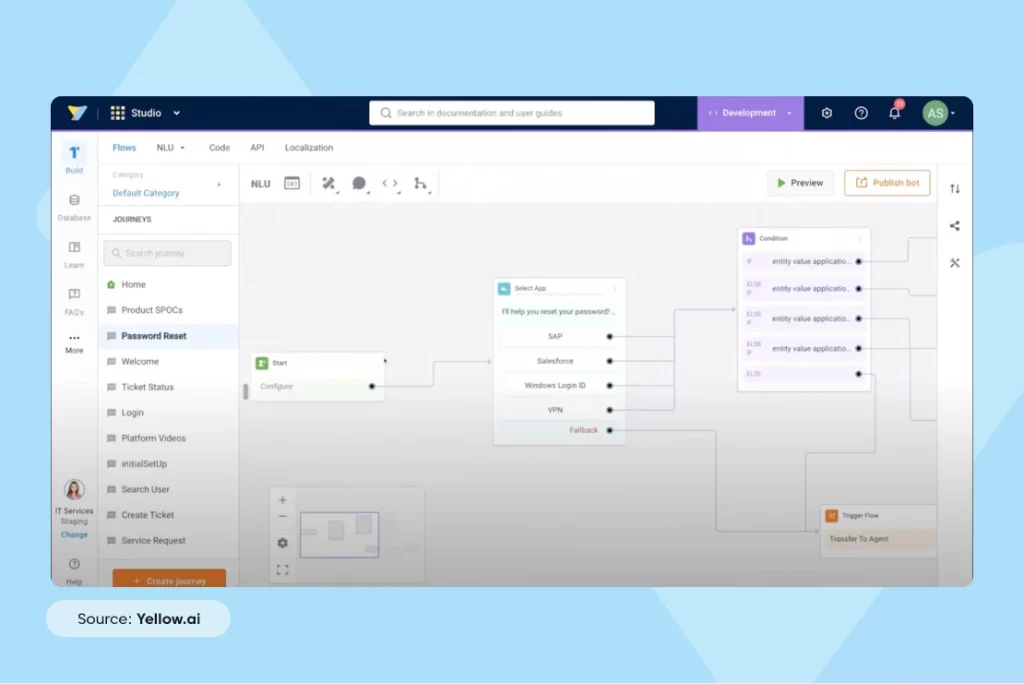
Leverage Yellow.ai’s automated utterance suggestion system to suggest different utterances as soon as the intent is created, creating an experience that will delight your customers.
Training/creating of new intent on the Yellow.ai platform
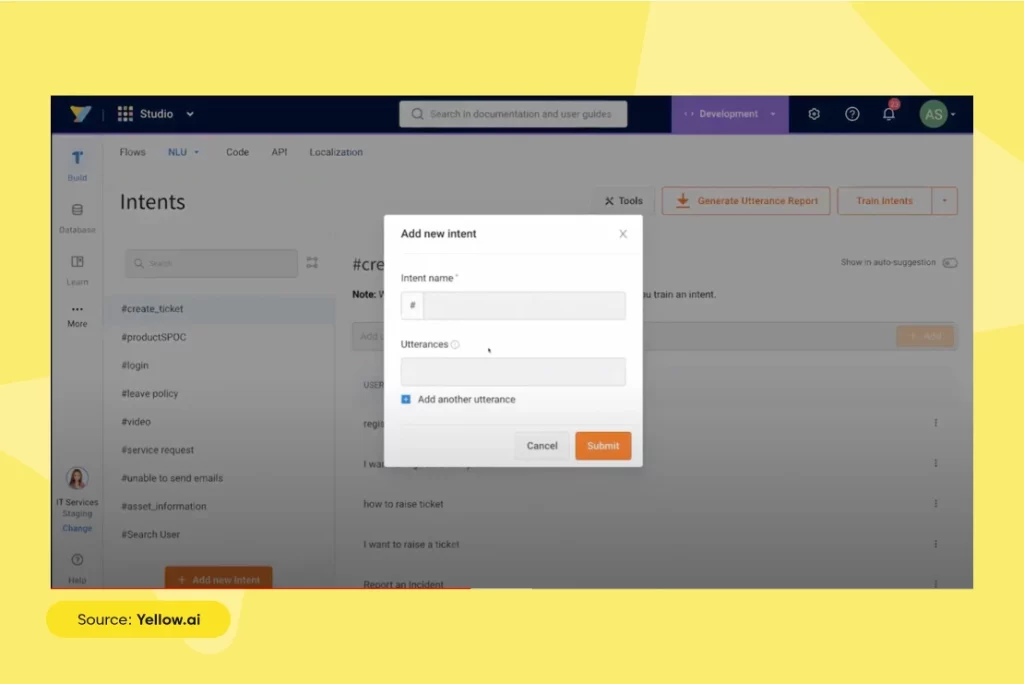
Below are the steps to help you understand how you can create new intent on Yellow.ai platform:
- Create intent and add a few sample utterances to get a list of more utterances (comes from the intent library) to improve bot accuracy.
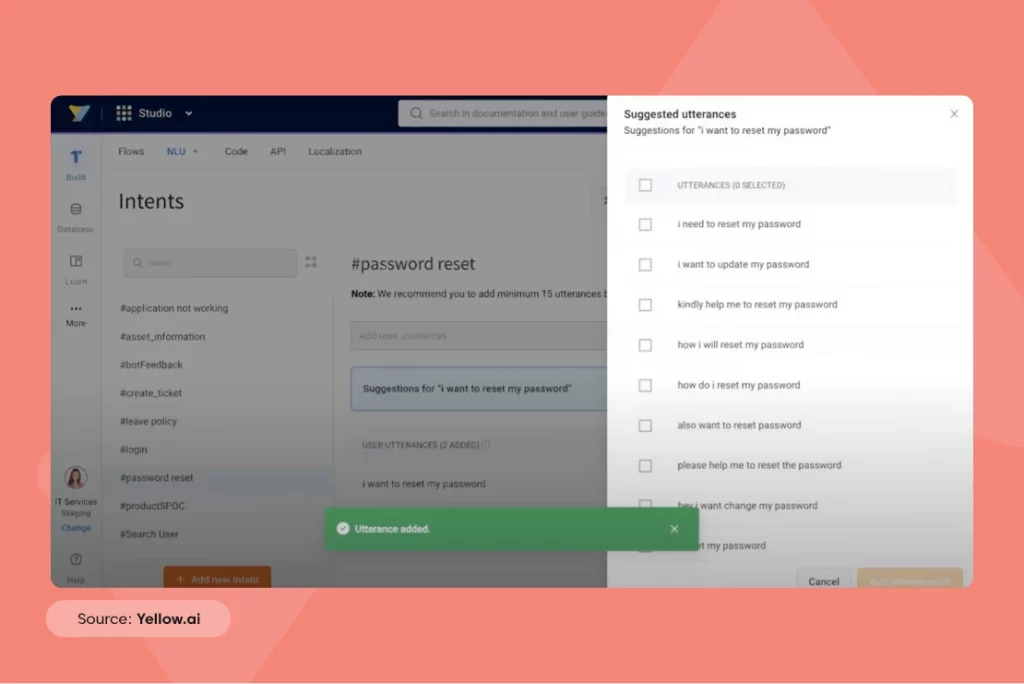
- In under 2 minutes, the Dynamic AI Agent is now able to understand the intent and you are set to respond to the query effectively!
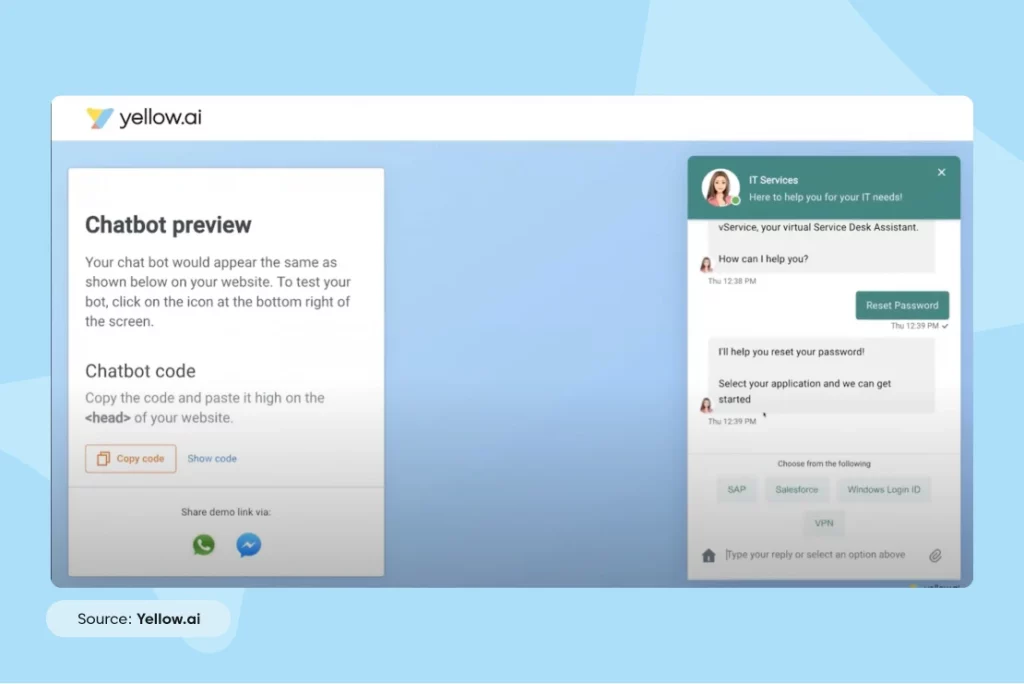
So, are you ready to engage and captivate your customers to deliver a superior customer experience? Talk to our experts today!




